
What we have done so far:
So far, we have gathered data from many balloons across 8 distinct directions. We have also gathered recordings of a phone-playback of a popular song from each of the 8 distinct locations, which we can use as the output of an LTI system, where the system impulse is defined by the recording of balloon data. As we know that convolution in time-domain is equivalent to multiplication in frequency, we can use this to compute what the original audio would sound at the center.
Frequency, Magnitude, and Phase Plots and Analysis
For Task 1,
We were able to listen to our recordings using headphones (Sennheiser HD800S) and were able to reasonably predict which direction a sound was coming from almost 100% of the time when comparing between opposite sides (especially East, West, NE, NW, SW, SE) although North and South directions were hard to predict unless played simultaneously.
For task 3, We can validate our process for replicating location by using the balloon popping to create an impulse response of a system that replicates direction, convolving it with a control sample of our “true audio”, and then performing a correlation with validation recordings of the “true audio” at that location to see how similar we can achieve the sound. We can compare this correlation to a correlation between the control and validation data to confirm that our algorithm has improved the correlation. The same process can be applied when we include other features to make the location quality more accurate.
From our balloon data, we can compute two major qualities that we learned from the paper by Xie, Bosun. Interaural Time Difference (ITD) and Interaural Level Difference (ILD), which are two essential cues that humans use to localize sound sources in the horizontal plane. By incorporating these cues into our spatial audio project, we can create a more realistic and immersive listening experience, especially for binaural rendering over headphones. ITD is done by finding the time difference between the left and right responses, while ILD is done by finding the level difference (in decibels) between the left and right responses.
Next, once we have the ITD and ILD information, we can apply these cues to our audio signals to create a spatial sound experience. To apply the ITD, we can delay the left or right channel's audio signal by the time delay corresponding to that location. To apply the ILD, we can adjust the left and right channel's amplitude or apply frequency-dependent gains based on the ILD values for respective locations.
Next, we can use the Head-Related Transfer Function to make a more binaural experience for our sound output. We do this by convolving the modified audio signals with an HRTF to simulate the sound's spatial characteristics which will sound more realistic, as the function closely simulates the effect of sound coming into a human ear. We can fine tune models for this based on research on HRTFs by Xie, Bosun as needed.
We can validate the spatial audio experience by testing our output on a sample of listeners, and see if they can identify the location of sounds in a blind test. Listeners can provide feedback on the accuracy of the sound localization and the overall immersion. Based on the feedback, we can refine the ITD and ILD values, customize our HRTF, or other spatial audio processing techniques which we will mention at the end of Task item #3.






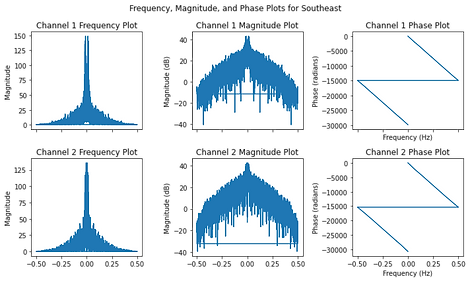

Initially, we expected to see differences in the phase of the signal between the left and right channels when analyzing the audio data from the different balloon pop locations. However, when we plotted the phase data, we found that it was consistent across all locations, which was unexpected. We then conducted further research and discovered that due to the symmetry in sound picked up by the left and right channels, there would not be much phase difference present in our recordings. Instead, the location properties of the sound would be more evident through the Interaural Time Difference (ITD) and Interaural Level Difference (ILD) measurements. As a result, we focused our analysis on ITD and ILD, and found that these measurements did indeed differ across the different balloon pop locations. While the phase data did not reveal any significant differences, the ITD and ILD data allowed us to identify and analyze the spatial characteristics of the sound produced by the balloon pops. The data on the ITD are compiled on the following page, Data.
Upcoming Tasks:
Some key tasks in the order we are working on (some simultaneously):
- Design a model of the HRTF that approximates the attenuation caused by the human head, known as the “head shadow” effect. We will use mathematically computed models for this filter using libraries such as pyroomacoustics, which will allow us to simulate raytracing within a simulated room and simulated head/ears. (in progress)
- Design a filter that approximates the high-frequency filtering caused by the pinna, known as pinna gain which is based directly on the direction that a sound comes from. We would likely create a system that checks the ILD and ITD values to determine how much (or little) of the input signal gets high-pass filtered. (in progress)
- Design an HRTF transfer function based on measurements. We can get these measurements from online HRTF databases such as the 3D3A Lab at Princeton University, and then use additional parameters to fine tune our own HRTF transfer function based on the data here as well as our own testing. We can compare the empirical HRTF to the one we produced based on our reading and code implementation. (in progress)
- Collect more sample data for a more robust validation of the impulse responses. We can pop more balloons and use some statistical algorithms (look for these algorithms) to ensure that our data is as accurate as possible.
- Research virtual sound reproduction techniques, how it relates to speaker vs headphone reproduction.
- Start researching how different wall materials and room geometries affect the sound, and potentially look into developing an additional component of our algorithm that can also simulate the sound reverberations that occur in different types of spaces. However, as we would like to focus our project more on the direction/location aspect in a single space, this would be a stretch goal.
Finished Tasks:
Tasks we have finished (date of completion):
- Create an algorithm to take in any audio input and modify the direction it is focused from. This is the main component/goal of our project thus far. We could do this using the ILD and ITD values learned from the sample data and the HRTF function that is still being adjusted to create binaural reproduction of audio data. We would combine the above to create an LTI system, which would then allow us to pass in any input to get the corresponding output.
Finished on April 8th, 2023
Our algorithm will also likely need to run analysis on the input sound file to be able to know how to tune it to reach the desired output. This could result in an algorithm that figures out which direction the input is coming from using auto-correlation techniques before applying the system described above.
Finished on April 8th, 2023
New Learnings:
Some of the new things we’ve learned are the characteristics of multi-channel audio, specifically Interaural Time Difference and Interaural Level Difference, as well as a technique known as Cross-Correlation, which is itself a type of correlation technique used in signal processing.
Most of the audio we hear is represented through a two-channel “stereo” system, which is the minimum number of channels that can be used to reproduce sound realistically, given consideration to the fact that humans have two ears. The key relevance of multiple channels became very apparent when we looked at time-domain, frequency-domain magnitude and phase plots of our testing data. We were able to find that there are characteristics known as Interaural Time & Level Difference, which are the time and level (in decibels) difference between the left and right channels of our recordings. We found that we can compute these using correlation, a concept in signal processing that allows us to measure similarity between the left and right side to find out the time delay between the two channels
In addition, we have learned a lot about the Head-Related Transfer Function, which will be explained in detail in the following page named after this feature. It is essentially the transfer function that models how sounds transform between the input (our ears) to the output (what we hear) and is the central topic around realistic sound.